

Coming from the world of Microsoft analytics, I got curious as to why Microsoft chose to go with “Fabric” as the name of the newly released analytical solution, Microsoft Fabric. Looking into this, the architectural concept of Data Fabric became more relevant. I had been working with Data Mesh for a while, but the Fabric architecture was something I had not heard that much about before. Of course, meant I needed to know more.
The plan was to write a short and easy blog about the differences between Fabric Architecture and Data Mesh and then see how these two architectures look inside Microsoft Fabric. Turns out there is too much to say, so I had to turn this into a mini-series. And first out, we have the Data Mesh architecture!
So, let’s have a look at what the Data Mesh is. What are the benefits of this architecture, and are there any limitations?
Stay tuned for more content on Fabric Architecture, and how Data Mesh and Fabric Architecture can be set up in Microsoft Fabric!
- What is Data Mesh Architecture?
- Why is the Data Mesh approach gaining traction?
- What are the different approaches you can have for Data Mesh?
- What are the main benefits of a Data Mesh Architecture?
- What are the main challenges of Data Mesh?
- So, is Data Mesh you enabler, or is it just creating a data mess?
What is Data Mesh Architecture?
Data mesh is both a data management approach and a data architecture. To be successful, it is not enough to only think about the architecture and technology, you might also need to change your organizational processes and structure. Having both IT and the business onboard is therefore a crucial success factor when implementing data mesh in your organization. In some ways, the data mesh approach brings data management and software architecture together.
Multiple great articles describe and define the data mesh approach. I will link these below, but also try to explain them here in my own words.
So, let’s do it! The data mesh approach comes from the domain-driven design and bounded context way of thinking. And we find these concepts in the 4 components that make up Data Mesh:
- Domains
- Products
- Federated Governance
- Self-Service Data Platform

Domains
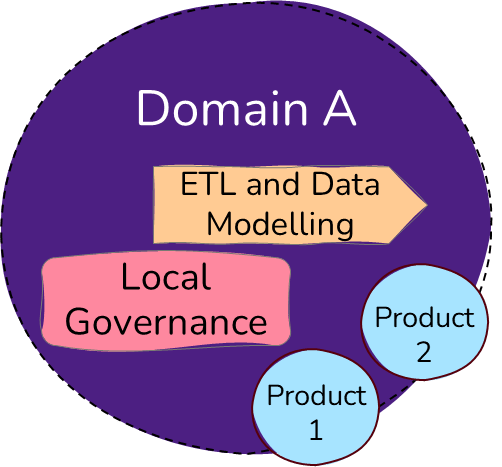
A domain is a grouping of data, technology, teams, and people that work within the same analytical realm, usually within a business area. Examples of domains could be the organizational structure, like Sales, Marketing, Finance, and HR. It can also be more fine-grained or connected to a value chain, like Orders, Production, and Distribution. All of this depends on your organization and how the domains would serve you and your business in the best way. The key thing here is that each domain can be autonomous and have ownership over the data products that naturally belong to their domain.
Since each domain is autonomous, they can develop their data products and govern these as desired. Still, the governance should be aligned with the centralized data governance. I will come back to this. The ETL and data modelling are also handled locally by the domain while taking advantage of the self-service data platform provided through the central organization.
Data Products
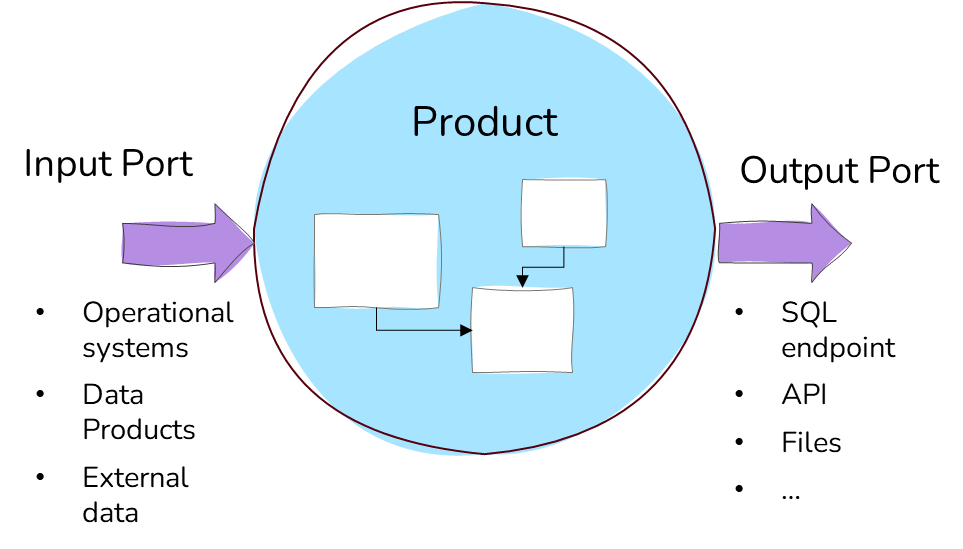
By introducing product thinking into the world of data, you get Data Products. A data product is a data asset that should be trusted, reusable, and accessible. The data product is developed, owned, and managed by a domain, and each domain needs to make sure that its data products are accessible to other domains and their data consumers.
This means that a domain can use data products from other domains to build their data products. It is these links that give the mesh of a data mesh with all the connections between the domains and the data products.
In practice, a data product can be many things. Examples could be a Power BI Dataset, a parquet file, an SQL table, a Power BI report, etc. The modelling of the data product and the needed ETL process to build the data products are handled by the domains.
Federated Governance

To make each domain autonomous in its data product development and management, a federated governance model is used. The federation of governance is a way of deferring responsibilities to enable scalability. It promotes independence and accountability. This way, the domains can govern their data products in a way that is effective and makes sense to them.
Still, there should be some centralized governance providing a set of standards, and best practices, setting the necessary boundaries, and being a center of excellence, providing expertise to the federated domains.
Self-serve Data Platform

The last component of the data mesh approach is the self-serve Data Platform. The self-serve data platform is a centralized service that serves the domains with their need for infrastructure, storage, security, access management, ETL pipelines and more. Some call this data infrastructure as a platform to highlight that the self-serve platform should serve the infrastructure, i.e. all the technical components and their integrations required to build data products.
The centralization of this service also enables some of the standardization in the centralized governance.
Still, what each organization puts inside the “Self-serve data platform” box might vary, and some open up for flexibility in technology choices.
Why is the Data Mesh approach gaining traction?
To understand this, it can help to have a look at what we are trying to move away from in the data and analytics world. Previously we have seen siloed proprietary enterprise data warehouses. They are complex, with long development processes, low scalability and high cost.
But it is not only the old data warehouse that is the challenge of organizations today. Also, the more modern concept of data lake has proven to be a challenge. The data lake has for some organisations become this big data box that holds all of the organization’s data, operated by a centralized and specialised team of data engineers. For many, this results in a siloed data lake that works as a bottleneck for developing new solutions and gaining new insights.
The monolithic data warehouse or data lake and the centralised operating model become the bottleneck for development and turning data into insights.

What are the different approaches you can have for Data Mesh?
There are also differences in how an organization might choose to interpret the data mesh approach. These are well described in the book Data Management at Scale (Strengholt, 2023) where Strengholt highlights different degrees of the data mesh interpretation, or different topologies as he calls it. I will briefly summarize the ones I find the most interesting below as I think it highlights some of the complexity of the data mesh.
Fully Federated Domain Topology

This solution has no central orchestration, with a strong emphasis on federation. Here you have fine-grained decoupling and high reusability. The domains themselves are independent and serve data products to other domains. You don’t have any central authority and the compliance is enforced through the centralized platform.
The benefit of this approach is the high degree of flexibility with few dependencies. It also promotes the reuse of data products, as there would naturally be a large production of data products.
The challenge with this fully federated approach is that the independence of the domains makes the critical need for harmonization on data interoperability, governance, security standards and metadata difficult. Alignment can be challenging. Also, the nature of fine fine-grained federation promotes more separation in the architectural setup, meaning that you might find the integration job of making all these fine-grained products talk to each other difficult.
The fully federated approach poses a challenge in terms of harmonizing data interoperability, governance, security standards, and metadata. The independence of each domain makes it difficult to align and integrate the fine-grained products. The nature of this approach promotes separation in the architectural setup, making it challenging to establish communication between these products. Also, if you need to pull data from multiple data products and domains to solve analytical needs, you will probably have a challenge with meeting the need for high data quality, performance and interoperability.
Decentralization also requires a significant level of independence and technical expertise within each domain. It requires a substantial pool of highly skilled data professionals who understand the intricacies of the data mesh methodology. To successfully adopt the data mesh approach, an organization must have sufficient traction and a wide array of data products that demonstrate the value of embracing a data product mindset. However, building and sustaining such teams of data professionals can be a substantial investment for any organization.
Governed Domain Topology
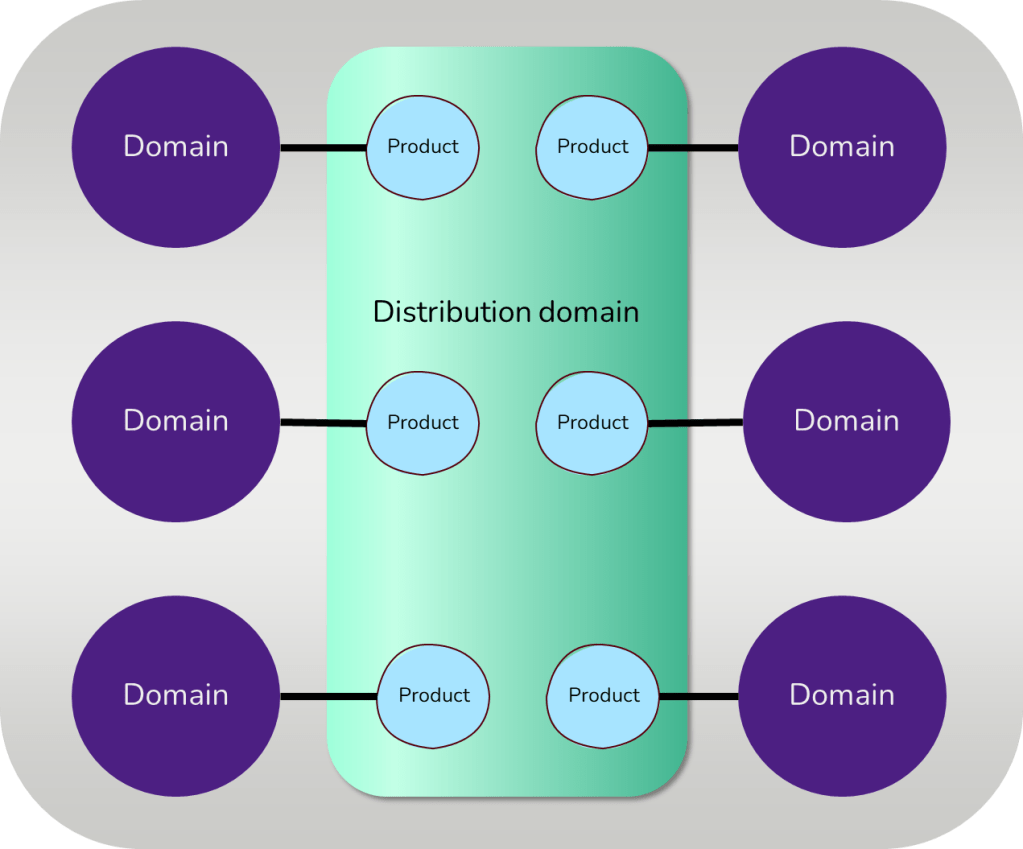
A step away from the most fined theoretical data mesh approach is to centralize parts of your mesh components. In the Governed Domain Topology, the data product architecture is centralized. This way, the consumption of data products is also centralized making them more discoverable. Integrations become less complex, and standardization on metadata, distribution or consumption is easier to implement and enforce.
Despite the numerous advantages, the central distribution of your data can sometimes become a bottleneck. Moreover, if your data landscape consists of various cloud providers or technologies, integrating them into a centralized data distribution can present a significant challenge.
Partially Federated Domain Topology

Other organizations might want to go all in on the data mesh approach, but due to their technical setup and/or lack of data engineers and resources need to go with a more centralized solution with some federation.
You can have partly centralized data on the source system side, while the consumption side is more distributed. I like to think of this as more centralization closer to the sources. Your first data transformation steps, as in the bronze layer of a medallion architecture, or your landing and transformation zone is centralized. While your distribution layer or gold layer adopts the data mesh topology.
The challenge with this is the possible bottleneck on the source site, as bringing new sources into the solution requires a centralized team of data engineers. Less autonomy for the data product consumers domain.
What are the main benefits of a Data Mesh Architecture?
Autonomy
The federation and domain-driven design bring about a paradigm shift in the way organizations approach software development. By advocating for independence and accountability, these methodologies empower teams to take ownership of their domain and develop autonomous solutions. This decentralization fosters a culture of innovation and agility, allowing teams to adapt quickly to changing requirements and market demands.
Scalability
The scalability of these methodologies is another key benefit. With each team operating independently and focusing on their specific domain, the overall system becomes highly scalable. This means that as the organization grows and new functionalities are required, additional teams can be introduced seamlessly without disrupting the existing ones. This modular approach enables organizations to effectively manage complex projects and easily accommodate future growth.
Closer collaboration between business and tehcnology
One of the notable advantages of the data mesh approach, which is closely aligned with domain-driven design, is the closer collaboration between business and technology. By placing ownership of data in the hands of the business, this approach enables better alignment between data management strategies and overall business goals. It encourages cross-functional communication and enhances the understanding of data within the organization. This alignment fosters a shared vision and empowers decision-makers to make informed choices based on business objectives.
What are the main challenges of Data Mesh?
Risk of creating isolated data hubs
The decentralization certainly enables scalability and high productivity, but it can also lead to chaos. Without a certain level of centralization where the organization as a whole can establish boundaries, standards, and best practices, there is a risk that each team will develop their architecture, and choose its technologies, standards, data formats, and more. This may result in each team being solely responsible for their data, creating isolated data hubs that cannot be combined or integrated with other domains. Consequently, the overall value proposition of a data mesh can be compromised.
Not serving the organizations data model
The concept of the data product approach challenges the notion that there is a single data model that applies to the entire organization. While this may hold to some extent, in reality, there are interconnected relationships between domains and data products within an organization that should be standardized and governed. These relationships play a crucial role in maintaining the integrity and quality of your data model.
Missing a harmonized strategy
More decentralization makes it more difficult to harmonize around a strategy and set centralized governance, boundaries and standards. You can end up with siloed data domains or multiple fragmented data warehouses, ultimately blocking one of our initial justifications for implementing the data mesh approach, the organizational scalability.
So, is Data Mesh you enabler, or is it just creating a data mess?
Short answer, it depends.
Even though there is some great literature out there explaining and even defining the how-to’s of a data mesh approach, the reality is that organizations quickly interpret the approach to fit their organizational structure.
That can play out in different emphasis on the centralised components of the data mesh structure, opening up for too much autonomy creating as the ultimate consequence siloed data domains that create data products that are not interoperable and consumable for the organization as a whole. It can also lead to data products with different interpretations of the data model that can ultimately result in different truths.
However, the data mesh approach is the result of the need to move away from the monolithic data warehouse or data lake and the centralised data engineering team. It does enable autonomy and scalability with its federation.
A key enabler for data mesh will therefore be, despite the decentralised focus, a centralised plan. A data strategy containing some standards, an architecture, overall governance and best practices or rules. This will help you ensure that your data mesh doesn’t become a mess.
Hope you found this article helpful!
Useful links:
- https://www.domainlanguage.com/ddd/
- https://www.oreilly.com/library/view/data-management-at/9781098138851/
- https://towardsdatascience.com/data-mesh-topologies-and-domain-granularity-65290a4ebb90
- https://www.thoughtworks.com/insights/articles/data-mesh-in-practice-organizational-operating-model
- https://www.thoughtworks.com/insights/articles/data-mesh-in-practice-product-thinking-and-development
- https://www.thoughtworks.com/insights/articles/data-mesh-in-practice-technology-and-the-architecture
- https://www.thoughtworks.com/insights/articles/data-mesh-in-practice-getting-off-to-the-right-start

One thought on “Is Data Mesh your enabler, or is it just creating a data mess?”
1 Pingback